This is another summary task given by my English teacher. He found a very informative tech magazine, called Open Source for You, which introduces a lot of useful and modern tech content. And this time the summary will be about natural language processing, especially about information extraction technique used by search engines and about a knowledge database canonicalization problem. It’s a very interesting topic for me and I’m thankful to my teacher for giving me such interesting topics for my writing.
Actually summary starts here.
‘Wh*’ factual questions
At the beginning, the author introduced the main idea of the article topic. The purpose of using a natural language processing on given text input is to extract some special information from it. If it will be done, it would save a lot of time for people. It’s not an easy task because the information could be provided from different sources and could be presented in different formats.
Search engines already have a functionality to provide answers to easy and typical questions, which started from one of the W words, like ‘What, where, when, who’. To give a short answer in special box, search engines use knowledge bases such as Wikipedia on a background. But not for all Wh* questions the answer could be found easily.
“Why did Al Gore concede the election?”
The most difficult questions for search engines is long questions which start with ‘Why’ word. For questions without a short answer, a search engine provides a list of search engine result pages. It happens because a search engine (SE) can’t process information like a human and can’t make assumptions or conclusions. It’s easy to answer the question like “Why is the sky blue”, because Wikipedia contains the univocal answer, but if a question is more difficult – there is no simple answer. SE haven’t enough confidence to provide a succinct answer to difficult questions. But in the result, it’s not so bad because usually the very first links from the result pages list are lead to a page with the answer. So, how information can be extracted more effectively?
It’s all about entities database
The main goal is to teach information extraction system to convert information from an unstructured form to a structured one and a suitable form for a specific domain. This kind of structured databases called ontology and they are consist of defined entity types. For example, a medicine ontology could contain entities like ‘disease’, ‘symptom’, ‘drug’ and describe relations between them.
To identify relevant entities mentioned in any set of text documents, huge or small, the Named Entity Recognition could be used. After that part will be done, a system should define an entity type.
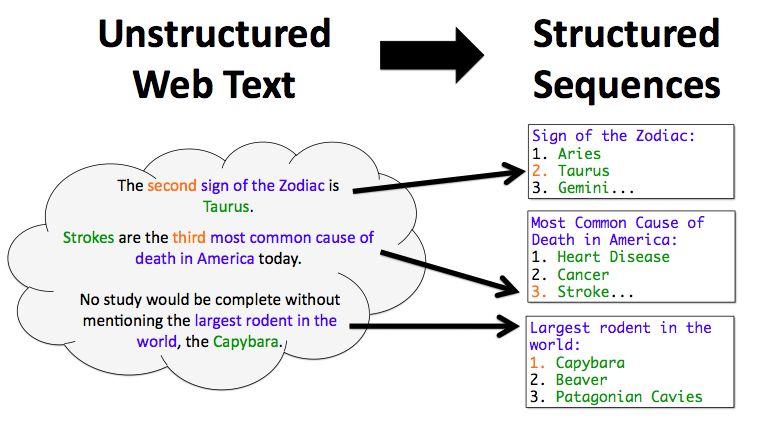
entities database structure
Entity typing techniques
There are three techniques used to typify entities: (a) the supervised technique, (b) the weakly-supervised technique, and (c) the distantly supervised technique. The supervised technique uses annotated data to classify each entity with a right type label and after that to learn a prediction function. The weakly-supervised technique uses a pattern based approach to do the same but using some set of instances and patterns at the start. If the pattern recognized in one case, on one sentence, it can be used on all document then.
Differences between weakly-supervised technique and the distantly supervised technique are, that for first one seed entities should be specified. But the distantly supervised technique could use any distant knowledge base to obtain seed entities.
The problem of canonicalization
There is a hard problem which should be solved. To describe this problem let’s assume, for example, that we have two sentences for analyzing, and in one sentence we have the disease named Diabetes, and in the second one, we have the Diabetes mellitus disease. Both of this named diseases could refer to the same entity or not. But a system should somehow decide to map these entities to a unique one entity or not. That is the canonicalization problem.
The system can’t leave such similar entities separated in two different rows because then users could get irrelevant results for their requests to SE. For example, if a question is what cause of the Diabetes, the answer is “Inadequate blood sugar control” and it should be right for the Diabetes mellitus too.
Things are not so easy as they seem to be
On first sight the problem could be solved by clustering this two diabetes entities by name, using words similarity in their names. But it will not work right, if, for example, a system will try to cluster information about diabetes 1st type and 2nd type together. Different types of diabetes need different treatment and drugs. If a system will do so then it couldn’t be possible to get the right answer about which drugs are used to treat specific diabetes type.
In the end of the article, the author leaves for readers an open question – what is the efficient technique for knowledge base canonicalization? Maybe it will be discussed in the next column.
Thank you for reading! This article was written for learning purposes because I’m attending English lessons.